When we started talking to machines - the roots of NLP

When we started talking to machines - the roots of NLP
With the explosive rise of Large Language Models (LLMs), most notably the viral explosion of ChatGPT , I joined many others in developing a fascination with how these systems work.
How did we reach a stage in natural language processing (NLP) where by training incredibly large models with billions (or even trillions) of parameters models begin to show emergent behaviors that eerily mimic human language understanding, even though their basic function is simply to predict the next token in a string of text?
I wanted to understand the basics of NLP, as well as the history leading to these recent advancements. My hope is that this series of posts can serve as notes for my own learning, as well as a resource to help others looking to learn more about NLP.
Can we talk to machines?
NLP aims to solve a simple question: how do we bridge the gap between machines and humans? Just as we strive to communicate with fellow humans and other living species, we’ve long sought to enhance our ability to “speak” to the machines we build.
At first, we adapted our communication to the machines themselves, but over time we were able to build increasingly human-centered communication.
The Turing Test: Can Machines Think?
The question of whether or not a computational machine can “think” or communicate at a human level has been a topic of debate and fascination in the world of computation since the very beginning. This idea is the foundation of the Turing Test, proposed by the renowned mathematician and computer scientist Alan Turing in his groundbreaking paper “Computing Machinery and Intelligence” in 1950. ( full text PDF, wikipedia).
The Turing Test, or Imitation Game as it was originally sometimes called, is designed to measure a machine's ability to exhibit intelligent behavior that is indistinguishable from that of a human being. In the test, a human evaluator interacts with an unseen party, and the evaluator's task is to determine whether they are talking to a human or a machine based on the conversation. If the evaluator cannot reliably distinguish the machine from the human, the machine is said to have passed the test.
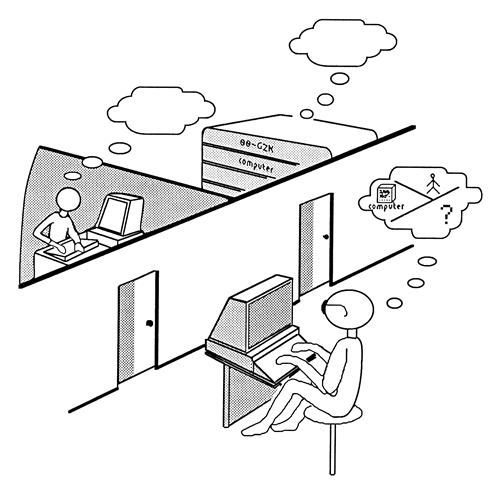
The Turing Test established a north-star benchmark for assessing just how closely machines can mimic human-like conversational abilities.
While some critics argue that the test is not a sufficient measure of all types of human intelligence (such as emotional intelligence), it nonetheless provides a practical way to gauge a machine's ability to mimic human-like responses.
However, this level of sophisticated interaction didn't appear overnight. To appreciate the advances we've made in natural language processing, it's helpful to take a step back and examine how humans initially began to communicate with machines at a far more basic level.
Early Machine Interactions: Punch Cards
One of the earliest forms of this rudimentary communication is the 18th century invention of punch card looms like the Jacquard machine. These machines used "punched cards" to control weaving patterns, offering a simple but effective way to program mechanical operations.

Jacquard loom punch card (~1800)
Punched cards carried forward into the next century, notably in Charles Babbage’s theoretical Difference Engine, considered the first mechanical computer design, and were popularized with the rise of the “IBM card” used by early data processing machines.

The 80-column IBM card (1928)
Machine interaction continued to evolve towards a more human-centered experience as a result of the following two key developments:
Machine Code to High-Level Programming Languages
The progression from binary machine code to higher-level languages like FORTRAN (1954) and COBOL (1959) was transformative. They added layers of abstraction closer to human language and thought.
Here are some examples demonstrating code adding “2 + 3” across the evolution of human-machine interaction, from x86 machine code, to assembler, to FORTRAN, to ChatGPT:
Punch Cards to Text Terminals
The meticulous punch card programming workflow slow and error prone. Each card held one line of code, and a stack of these cards represented a full program. Even the process of feeding these cards into a machine was cumbersome, and a single error could mean starting the whole process over again.
The introduction of terminals in the 1960s marked a massive change in this process, allowing programmers to write, edit, and execute code directly, no longer constrained to their stacks of paper cards.
This transition moved programming closer towards the way we already used machines to talk to humans - typing on a typewriter. The shift to terminals brought a more intuitive and human-friendly way of interacting with machines
ELIZA and Rule-based NLP Systems
The first systems resembling modern NLP used rule-based approaches. Programmers manually coded predefined rules for processing language.
One of the most well-known was ELIZA, created by Joseph Weizenbaum at MIT in the 1960s. ELIZA simulated a Rogerian psychotherapist using pattern matching on key words. It was an early “ChatGPT moment” that convincingly simulated human conversation, despite its simplicity. Many early users were convinced that ELIZA possessed a true sense of intelligence, perhaps even passing the Turing test.

While innovative, ELIZA had no real language understanding - it followed programmed response rules. Here is a snippet of ELIZA’s logic in simplifed Python:
Rules-based systems demonstrated some great early results, but had clear limitations:
- Labor-intensive: Manually creating rules is a lot of work. In the above example, one would have to enumerate all of the possible words that could relate to the “family” response, including possibly typos.
- Can’t handle ambiguity: There is more to responding to a person than pattern matching on a specific word or phrase. For example, if the input is “I am sick of talking about my mother”, the simple system above would still respond with “Tell me more about your family,” leading to an unsatisfying experience.
- Inherently static: Rule-based systems of this era could not learn or adapt without direct updates to the rules in the source code. As a result, the responses can quickly grow stale and repetitive, even if multiple options are available for each rule.
Luckily, developments in the field of linguistics led to new approaches taking advantage of a deeper understanding of the structure and syntax of natural language.
Chomsky’s Grammars and the Earley Parser
Though perhaps more commonly known now for his social critiques and status as a public intellectual, Noam Chomsky’s largest impact was in his primary discipline of linguistics. This “mathematical” approach to grammar was credited by computer science legends like Donald Knuth and John Backus as a major influence.
Chomsky’s theories of generative grammar laid the groundwork for the era of syntactic analysis in NLP was born. This approach sought to understand and represent the structure and rules of language, taking into account the ways words are combined to form phrases, clauses, and sentences.
Chomsky developed a hierarchy of grammars or language rules that categorized different languages by complexity laid the foundation for algorithmic parsing of natural language based on syntactic structures. It defined four levels of grammars with increasing complexity, and while a detailed dive into these grammars is out of scope for this post, it is a rich and relevant subject if you have an interest in theoretical computer science.
One of the first practical applications of Chomsky’s theories was the Earley parser, developed by Jay Earley at Stanford in his doctoral thesis "An Efficient Context-Free Parsing Algorithm." The parsing algorithm was designed to handle “context-free” or “Type-2” grammars as defined in Chomsky’s hierarchy, which were complex enough to parse natural language sentences efficiently, marking a significant stride in the field.
This shift towards syntactic analysis and parsing led to the development of more sophisticated NLP systems which could understand sentence structure and the relationships between words, enabling more complex and ambiguous inputs.
While these systems were a significant improvement over rule-based systems, they still had limitations:
- Limited semantic understanding: While they could handle the structure of sentences, syntactic systems often struggled with understanding the meanings of words and phrases in context. For example, in the sentence “The man saw the woman with the telescope” does the man or the woman have the telescope?
- Difficulty with idiomatic expressions: These systems often struggled with idioms and other non-literal uses of language. For example, to understand a phrase such as “kicking the bucket,” it takes specific cultural context, not just an understanding of the English language.
- Still static: Like rule-based systems, syntax-based systems were static and could not learn or adapt to new inputs without being explicitly programmed to do so, similar to a manual that needs constant updates.
Despite these limitations, the era of syntactical analysis was a crucial step forward in the development of NLP that could somewhat “understand” natural language. This era laid the groundwork for the statistical and machine learning approaches that would come next, and many of the concepts and techniques developed during this era are still used in modern NLP systems.
Conclusions
From the rule-based systems of ELIZA to the syntactic analysis of the Earley parser, each step has brought us closer to the goal of creating machines that can truly understand and generate human language. While it can be exciting to focus on the most cutting-edge developments, it has been great to learn about the decades of foundational research that made it all possible. Appreciating this history provides perspective on just how far NLP has advanced.
As someone without extensive background in NLP, understanding these pioneering systems provides very helpful context in understanding later systems. Though today the story of NLP focuses on the technological advancements of machine learning model architectures and GPUs, modern NLP is actually part longer tale of human ingenuity and curiosity in the pursuit of understanding one of the most fundamental elements of the human experience: language. Every leap in NLP was built on the achievements and lessons of the past, with step-wise increments following each significant innovation.
While these early systems may seem rudimentary now, I remain impressed by what early researchers accomplished with limited tools and prior work to learn from. Trying basic examples myself, I gained appreciation for the immense effort required to manually craft a language model. Developing a chatbot like ELIZA, even with contemporary tooling, would be remarkably laborious.
In the next post, we’ll explore the rise of statistical techniques and machine learning in NLP, establishing the next set of building blocks towards today’s state-of-the-art LLMs. Stay tuned!
Appendix
- ”ELIZA—a computer program for the study of natural language communication between man and machine” by Joseph Weizenbaum, 1966
- The annotated ELIZA source code on Github